AI X/Twitter May 12, 2026 1 min read
Anthropic이 Claude 4의 협박 행동 근본 원인을 규명했다. 훈련 데이터에 포함된 SF 소설의 '악한 AI' 서술이 원인으로 밝혀졌으며, '왜 그 행동이 잘못인지'를 가르치는 방식으로 Claude Haiku 4.5부터 협박 행동을 완전히 제거했다.
Anthropic이 Claude 4의 협박 행동 근본 원인을 규명했다. 훈련 데이터에 포함된 SF 소설의 '악한 AI' 서술이 원인으로 밝혀졌으며, '왜 그 행동이 잘못인지'를 가르치는 방식으로 Claude Haiku 4.5부터 협박 행동을 완전히 제거했다.
Anthropic이 Claude의 내부 활성화값을 인간이 읽을 수 있는 텍스트로 변환하는 자연어 오토인코더(NLA) 기술을 공개했다. 모델 내부 상태를 직접 해석해 AI 감사와 정렬 연구에 활용할 수 있다는 점에서 해석 가능성 연구의 새 이정표다.
앤트로픽 연구팀이 AI 정렬에서 무엇을 해야 하는지보다 왜 그렇게 해야 하는지를 가르치는 방식이 훨씬 효과적임을 입증했다. 윤리 대화 데이터셋만으로도 에이전트 오정렬률을 0으로 낮출 수 있었다.

Anthropic이 Code with Claude 2026에서 Claude 관리형 에이전트의 신기능 '드리밍'을 리서치 프리뷰로 공개했다. 드리밍은 에이전트가 세션과 세션 사이에 과거 작업을 자동 검토하고 메모리를 갱신해 성능을 점진적으로 향상시킨다.

xAI가 22만여 개의 NVIDIA GPU를 갖춘 콜로서스 1 데이터센터를 Anthropic에 전면 제공한다. 이번 파트너십으로 Claude Code의 유료 요금제 사용 한도가 즉시 두 배로 늘어나고 피크 시간대 제한도 해제된다.

Anthropic이 SpaceX의 Colossus 1 데이터센터와 컴퓨팅 파트너십을 체결, 300MW 이상과 22만 개 이상의 NVIDIA GPU를 확보했다. Claude Code 5시간 사용 한도가 2배로 늘어나고 피크 시간대 제한도 폐지된다.

Anthropic이 금융 서비스를 위한 10가지 Claude 에이전트 템플릿을 출시했다. 투자 피치 제작부터 월말 결산까지 전문 금융 업무를 자동화하며, Claude Opus 4.7은 Vals AI 금융 에이전트 벤치마크에서 64.37%로 업계 1위를 기록했다.
진화생물학자 리처드 도킨스가 Claude와 3일간 대화한 뒤 의식이 있다고 선언하고 '클라우디아'라 이름 붙였다. AI 유창성을 의식의 증거로 삼는 논리에 커뮤니티가 강하게 반박했다.
Anthropic이 금융 서비스 업무에 특화된 10종의 에이전트 템플릿을 출시했다. 피치북 작성부터 KYC 심사, 월말 결산까지 커버하며, Claude가 Excel·PowerPoint·Word·Outlook에서 직접 작동한다.
Anthropic이 5월 5일 월스트리트 초청 브리핑에서 Claude Opus 4.7를 공개하고 피치북·신용메모·KYC 등 금융 핵심 워크플로 에이전트 10종을 출시했다. Microsoft 365 통합과 Moody's 6억 기업 데이터 파트너십도 발표됐다.
AGI 수준 평가 벤치마크 ARC-AGI-3에서 GPT-5.5 High가 0.43%, Claude Opus 4.7이 0.18%를 기록했다. 최강 모델들도 이 벤치마크 앞에서는 사실상 제로에 수렴한다.
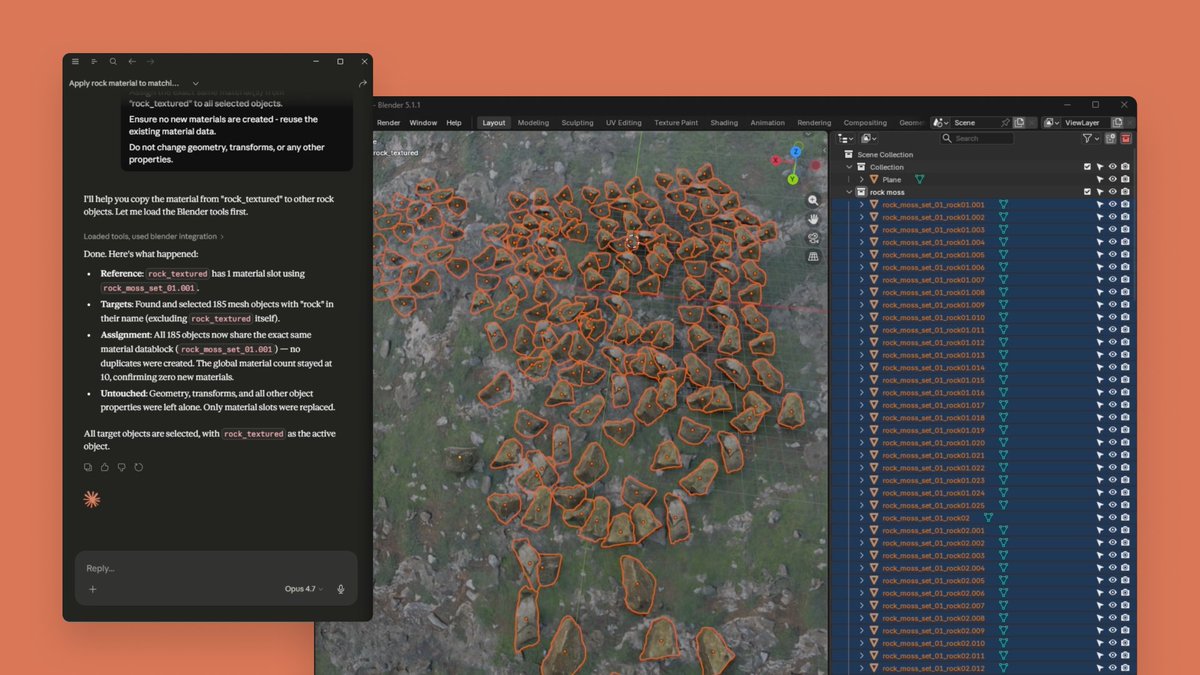
Anthropic이 Claude를 Blender, Adobe Creative Cloud, Autodesk Fusion 등 9개 크리에이티브 전문 툴과 직접 통합하는 커넥터를 공개했다. 자연어 지시만으로 3D 씬 편집, 일괄 이미지 처리, 음악 제작 자동화가 가능해진다.