AI X/Twitter May 2, 2026 1 min read
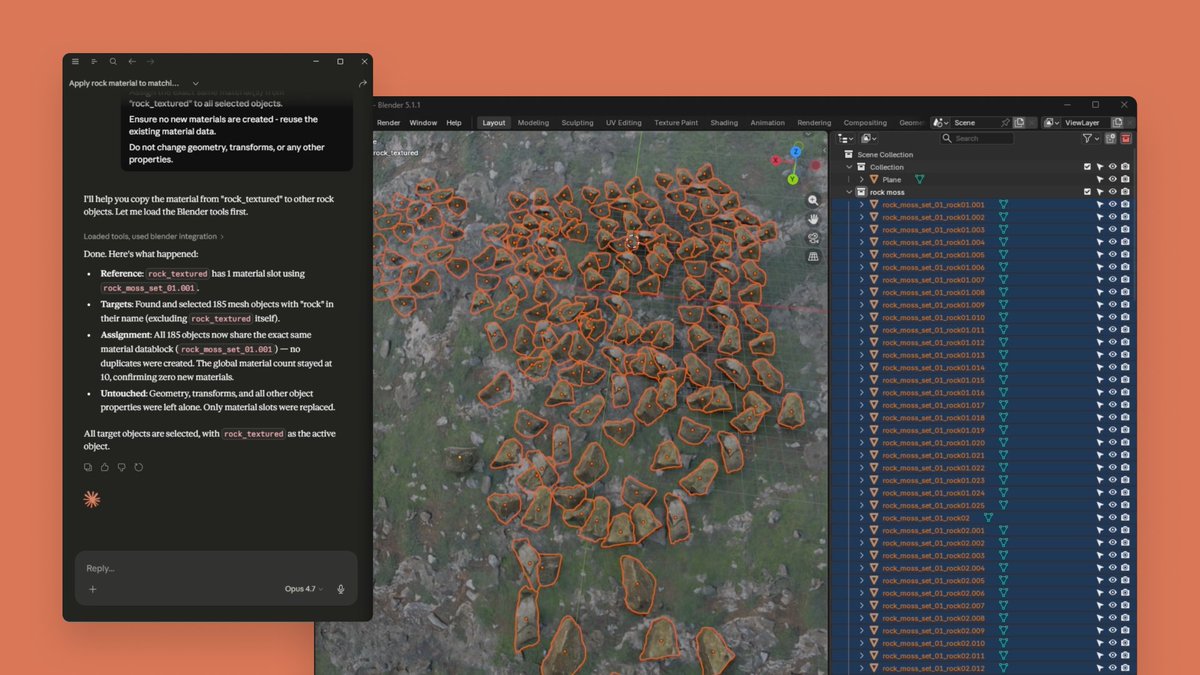
Anthropic unveiled 9 connectors linking Claude directly to creative professional tools including Blender, Adobe Creative Cloud, and Autodesk Fusion. Creators can now debug scenes, batch-process images, and automate music production through natural language commands.
